Overview
Modern scientific applications generate massive amounts of data, and the majority of their runtime is spent in IO. In order to counteract this IO bottleneck, distributed buffering systems such as DataWarp and Hermes have been created. Instead of writing data to permanent mass storage immediately, we can write to fast temporary storage and then asynchronously move that data to permanent storage. In this way, our application doesn't have to pay the penalty of moving the data to permanent storage every single time it needs to write something. However, temporary storage fills up quickly, and data stalls will still occur. We can use compression in order to increase the effective capacity of temporary storage to make this happen less frequently. In this work, we designed and implemented HCompress: a C++ library for buffering and compressing data in a distributed storage environment. The compression selection engine matches different compression libraries to different storage devices. This works off of the principle that slower storage devices tend to have more capacity and don't need to spend much time on compression, whereas faster storage devices have less capacity and should try to get a higher compression ratio. In our trials, we found that HCompress improved real-world workloads by as much as 700%.
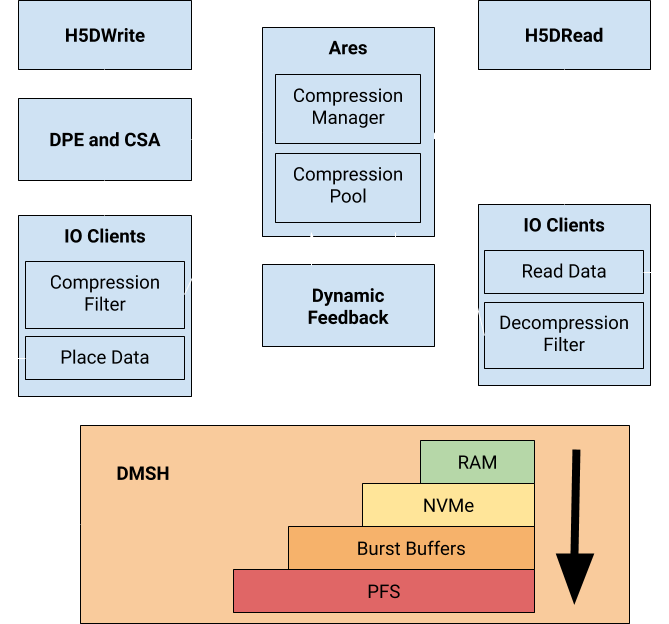
In this project, my role was to create the compression selection engine and integrate it into the data placement engine in Hermes, a modern solution for buffering data in a storage system. This involved modifying Ares: a unified interface to different compression libraries. I was responsible for adding new libraries, fixing bugs in the old implementation, and changing the metadata stored by Ares.
System Description
-
Distributed Memory and Storage Hierarchy (DMSH)
The DMSH represents the set of storage devices in a distributed system. Storage devices are grouped into tiers, and then into layers. A tier is a set of devices with similar architecture. For example, the set of all RAM devices in the entire distributed system would be in the RAM tier. Layers group devices based on their performance characteristics. For example, RAM-1600Mhz and RAM-3200MHz would be in two separate layers in the RAM tier.
-
The API
HCompress can be dynamically linked with applications that use the HDF5 interface. Using HDF5 VOL plugins, HCompress transparently intercepts calls to HDF5 and uses our hierarchical compression and data placement engine (HCDP) to store the data in the DMSH. We intercept calls to H5DWrite and H5DRead (writing and reading datasets). At the runtime of the user application, the user must define the storage devices in the network using an XML schema. The user defines the performance characteristics of the storage devices as well as the location of the storage device in the network.
-
System Monitor
In the background, HCompress will gather statistics about the tiers in the DMSH. It will periodically determine a device's availability and current capacity using built-in tools like du and iostat.
-
Ares
Ares is a compression service that unifies the interfaces of multiple different compression libraries: bzip2, zlib, huffman, brotli, bsc, lzma, lz4, lzo, pithy, snappy, and quicklz. When using the compression service, the user must specify which compression library they want to use, the data they want to compress, and the size of that data. Ares will allocate a buffer for storing the compressed data and then compress the input data by calling the chosen library from the Compression Library Pool. If the compression library ends up increasing the size of the data, the uncompressed data will be used instead. The buffer holding the data to return will be prepended with metadata including the uncompressed size of the data and whether or not the data is compressed. We do not store the compression library used in the metadata. We will assume the user remembers which library was used to compress the data when they go to decompress it.
-
HCDP
The HCDP decides where to put data in the DMSH and which compression libraries to use when compressing the data. This computation is based off of each device's capacity and performance as well as each compression library's performance and estimated compression ratio. After finding the least costly data placement, we actually place the data there. When placing data in the DMSH, we use HDF5 filters to divide the dataset into 1MB chunks. The filter will compress each chunk using Ares.
The data placement is determined as follows:
- \(S\) is the size of the data to be stored in DMSH
- \(i\) is the tier
- \(j\) is the compression library
- \(dmsh(S, i, j)\) is the time it takes to store S bytes in the DMSH starting from tier i using compression j
- \(tier(S, i, j)\) is the time it takes to store S bytes in tier i using compression j
- \(C_i\) is the capacity of tier i
- \(R_i\) is the remaining capacity of tier i
- \(B_i\) is the bandwidth of tier i
- \(t_c(S, j)\) is the time it takes to compress S bytes of data using compression j
- \(r(j)\) is the compression ratio for compression j
- \(t_d(S, j)\) is the time it takes to decompress S bytes of data using compression j
- \(S_j\) is the compressed size of S bytes using compression j
- \(w_1, w_2, w_3\) are user-defined weights
$$ tier(S, i, j) = w_1 t_c(S, j) + S_j/B_i - w_2(S_j/B_i)\frac{r(j)-1}{r(j)} + w_3 t_d(S_j, j) $$
$$ \begin{equation*} dmsh(S, i, j) = Min \begin{cases} tier(S, i, j) & S_j \lt R_i \\ tier(S, i, j) + dmsh(S_j - C_i, i+1, j) & R_i \lt S_j \leq C_i \\ tier(R_i, i, j) + dmsh(S_j - R_i, i+1, j) & C_i \lt S_j \\ dmsh(S, i, j+1) & \\ dmsh(S, i+1, j) & \\ \end{cases} \end{equation*} $$
-
Compression Cost Predictor
Every time a compression or decompression is made using the HCDP, we record the compression time, compression ratio, and the decompression time. Periodically, for each compression library, we will run a least squares regression using DLIB in order to estimate compression time, compression ratio, and decompression time in the HCDP.
The models we have for these are as follows:
\(c_1, c_2, c_3\) are parameters we are trying to estimate $$ t_c(S, j) = c_1 * S $$ $$ r(j) = c_2 $$ $$ t_d(S, j) = c_3 * S $$